Tutorial 9: Utility Functions#
This tutorial provides a hands-on tour of the utility functions in brutus.utils.
These functions underpin much of the core analysis in brutus but are also useful
on their own for photometric conversions, statistical computations, and posterior
sampling.
Topics Covered#
Photometry conversions – magnitudes, luptitudes, and flux arithmetic
Photometric likelihoods – standard and outlier models
Mathematical utilities – matrix inversion, positive-definiteness checks, distribution functions
Sampling utilities – weighted quantiles, multivariate normal sampling, posterior draws
Prerequisites#
This notebook requires no external data files. All demonstrations use synthetic data generated on the fly.
# Setup: imports and plot style
import warnings
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
# Tutorial utilities
from tutorial_utils import (
setup_tutorial,
save_figure,
print_section,
assert_array_properties,
)
# Run the standardized tutorial bootstrap
info = setup_tutorial(9, title="Tutorial 09: Utility Functions")
# Matplotlib defaults for this notebook
plt.rcParams["figure.figsize"] = (10, 6)
Tutorial 09: Utility Functions
==============================
Checking data requirements for Tutorial 9
=========================================
All required files available
1. Photometry Conversions#
brutus works internally with linear flux densities rather than magnitudes.
The brutus.utils module provides functions for converting between the two
representations, as well as support for asinh magnitudes (“luptitudes”) that
behave better at faint flux levels.
Key functions#
Function |
Description |
|---|---|
|
Flux to AB magnitude |
|
AB magnitude to flux |
|
Flux to asinh magnitude (Lupton et al. 1999) |
|
Asinh magnitude to flux |
|
Combine fluxes in magnitude space |
Note on units: brutus accepts photometry as linear flux densities |
|
in native survey units – specifically “maggies” (i.e., $10^{-0.4m}$ |
|
where $m$ is the magnitude in native survey units). The conversion |
|
functions below ( |
|
transformation between magnitudes and this linear flux representation. |
from brutus.utils import magnitude, inv_magnitude
print_section("1a. Magnitude / Flux Round-Trip")
# Create synthetic magnitude data: 5 objects, 4 filters
np.random.seed(42)
mag_orig = np.random.uniform(14, 22, size=(5, 4))
mag_err_orig = np.random.uniform(0.01, 0.1, size=(5, 4))
print("Original magnitudes (first object):")
print(f" mag = {mag_orig[0]}")
print(f" mag_err = {mag_err_orig[0]}")
# Convert mag -> flux -> mag
flux, flux_err = inv_magnitude(mag_orig, mag_err_orig)
mag_recovered, mag_err_recovered = magnitude(flux, flux_err)
print("\nRecovered magnitudes (first object):")
print(f" mag = {mag_recovered[0]}")
print(f" mag_err = {mag_err_recovered[0]}")
# Verify round-trip
mag_residual = np.max(np.abs(mag_orig - mag_recovered))
err_residual = np.max(np.abs(mag_err_orig - mag_err_recovered))
print(f"\nMax magnitude residual : {mag_residual:.2e}")
print(f"Max error residual : {err_residual:.2e}")
assert np.allclose(mag_orig, mag_recovered, atol=1e-12), "Magnitude round-trip failed"
assert np.allclose(mag_err_orig, mag_err_recovered, atol=1e-12), "Error round-trip failed"
print("\nRound-trip verified: mag -> flux -> mag is exact.")
1a. Magnitude / Flux Round-Trip
===============================
Original magnitudes (first object):
mag = [16.99632095 21.60571445 19.85595153 18.78926787]
mag_err = [0.06506676 0.02255445 0.03629302 0.04297257]
Recovered magnitudes (first object):
mag = [16.99632095 21.60571445 19.85595153 18.78926787]
mag_err = [0.06506676 0.02255445 0.03629302 0.04297257]
Max magnitude residual : 3.55e-15
Max error residual : 1.39e-17
Round-trip verified: mag -> flux -> mag is exact.
from brutus.utils import luptitude, inv_luptitude
print_section("1b. Luptitude (Asinh Magnitude) Round-Trip")
# Use the same synthetic flux data from above
skynoise = 1e-9 # softening parameter
# flux -> luptitude -> flux
lupt, lupt_err = luptitude(flux, flux_err, skynoise=skynoise)
flux_recovered, flux_err_recovered = inv_luptitude(lupt, lupt_err, skynoise=skynoise)
print("Original flux (first object):")
print(f" flux = {flux[0]}")
print(f"\nRecovered flux (first object):")
print(f" flux = {flux_recovered[0]}")
flux_residual = np.max(np.abs(flux - flux_recovered))
print(f"\nMax flux residual: {flux_residual:.2e}")
assert np.allclose(flux, flux_recovered, rtol=1e-10), "Luptitude round-trip failed"
print("Round-trip verified: flux -> luptitude -> flux is exact.")
# Compare magnitude vs luptitude for the same data
mag_from_flux, _ = magnitude(flux, flux_err)
print(f"\nMagnitude vs Luptitude (first object):")
print(f" mag = {mag_from_flux[0]}")
print(f" lupt = {lupt[0]}")
print(f" diff = {mag_from_flux[0] - lupt[0]}")
print("\nFor bright sources the two systems are nearly identical.")
1b. Luptitude (Asinh Magnitude) Round-Trip
==========================================
Original flux (first object):
flux = [1.59027276e-07 2.27884202e-09 1.14187716e-08 3.04995092e-08]
Recovered flux (first object):
flux = [1.59027276e-07 2.27884202e-09 1.14187716e-08 3.04995092e-08]
Max flux residual: 2.12e-21
Round-trip verified: flux -> luptitude -> flux is exact.
Magnitude vs Luptitude (first object):
mag = [16.99632095 21.60571445 19.85595153 18.78926787]
lupt = [16.99627802 21.43966326 19.84771879 18.78810257]
diff = [4.29294498e-05 1.66051189e-01 8.23274868e-03 1.16530448e-03]
For bright sources the two systems are nearly identical.
from brutus.utils import add_mag
print_section("1c. Adding Magnitudes (Combining Fluxes)")
# Two equal-brightness stars: combined flux should be double,
# which is -2.5 * log10(2) ~ -0.75 mag brighter.
mag1 = np.array([15.0, 18.0, 20.0])
mag2 = np.array([15.0, 18.0, 20.0])
mag_combined = add_mag(mag1, mag2)
expected_shift = -2.5 * np.log10(2)
print(f"Two equal stars (mag = {mag1}):")
print(f" Combined = {mag_combined}")
print(f" Expected = {mag1 + expected_shift}")
print(f" Shift = {expected_shift:.4f} mag (= -2.5 * log10(2))")
assert np.allclose(mag_combined, mag1 + expected_shift, atol=1e-12)
# Unequal stars: 5-mag difference means 100x flux ratio
mag_a = np.array([15.0])
mag_b = np.array([20.0])
print(f"\nBright (mag=15) + faint (mag=20):")
print(f" Combined = {add_mag(mag_a, mag_b)[0]:.4f} (barely changes the bright star)")
1c. Adding Magnitudes (Combining Fluxes)
========================================
Two equal stars (mag = [15. 18. 20.]):
Combined = [14.24742501 17.24742501 19.24742501]
Expected = [14.24742501 17.24742501 19.24742501]
Shift = -0.7526 mag (= -2.5 * log10(2))
Bright (mag=15) + faint (mag=20):
Combined = 14.9892 (barely changes the bright star)
1d. Magnitude vs Luptitude at Faint Fluxes
==========================================
Saved: /home/user/brutus/tutorials/plots/tutorial_09/mag_vs_luptitude.png
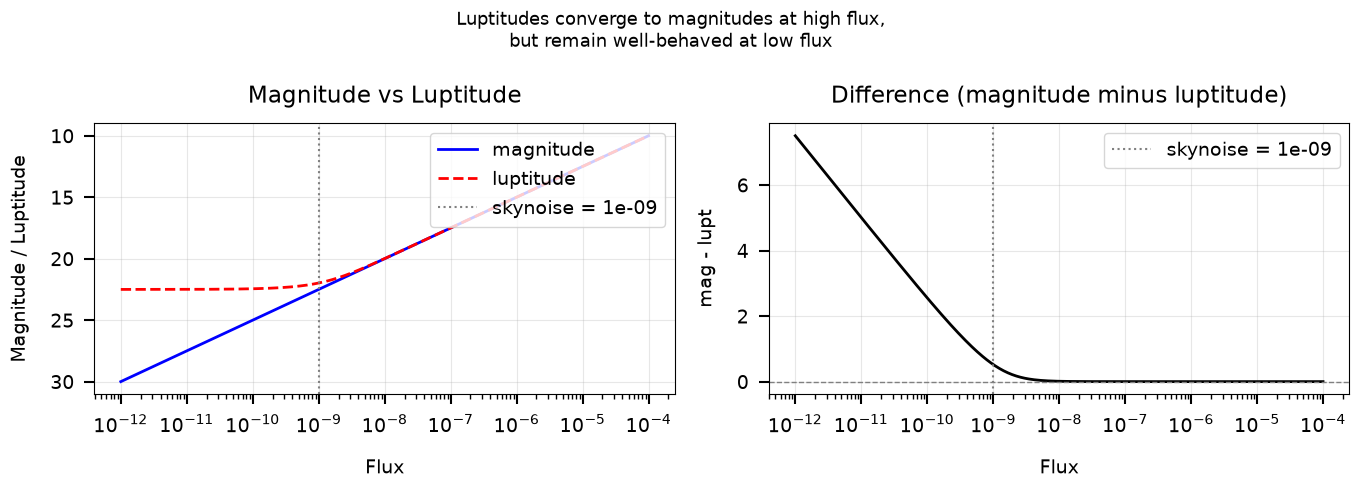
At bright fluxes the two systems agree to < 0.001 mag.
Near the sky noise level, luptitudes remain finite while magnitudes diverge.
2. Photometric Likelihoods#
The phot_loglike function computes the log-likelihood of observed photometry
given a set of model fluxes. Two additional functions provide outlier models:
Function |
Description |
|---|---|
|
Standard Gaussian photometric log-likelihood |
|
Chi-square based outlier model (for |
|
Uniform-over-data-range outlier model (for |
Note: uniform_outlier_loglike returns a proper log density in flux
space (uniform over the observed flux range in each band, padded by
sigma_clip errors), so its value depends on the flux units and data range
and is directly comparable to the Gaussian inlier density.
from brutus.utils import phot_loglike
from brutus.utils.photometry import chisquare_outlier_loglike, uniform_outlier_loglike
print_section("2a. Photometric Log-Likelihood")
np.random.seed(123)
# One observed object with 5 filters
Nfilt = 5
true_flux = np.array([[1.0, 2.0, 3.0, 1.5, 0.8]]) # shape (1, 5)
obs_err = np.array([[0.1, 0.15, 0.2, 0.12, 0.08]]) # shape (1, 5)
# Create 100 model fluxes: good match, mediocre, and poor
Nmod = 100
# Models are spread around the truth with varying offsets
offsets = np.linspace(-1.5, 1.5, Nmod)
model_fluxes = true_flux[:, None, :] + offsets[None, :, None] * obs_err[:, None, :]
# shape: (1, 100, 5)
# Compute log-likelihoods
lnl = phot_loglike(true_flux, obs_err, model_fluxes)
lnl_dim = phot_loglike(true_flux, obs_err, model_fluxes, dim_prior=True)
print(f"Observed flux shape : {true_flux.shape}")
print(f"Model flux shape : {model_fluxes.shape}")
print(f"Log-likelihood shape : {lnl.shape}")
print(f"\nBest log-likelihood (no dim_prior) : {lnl.max():.4f}")
print(f"Best log-likelihood (dim_prior) : {lnl_dim.max():.4f}")
assert_array_properties(lnl, name="lnl", ndim=2, shape=(1, Nmod), finite=True)
print("\nLog-likelihood array properties verified.")
2a. Photometric Log-Likelihood
==============================
Observed flux shape : (1, 5)
Model flux shape : (1, 100, 5)
Log-likelihood shape : (1, 100)
Best log-likelihood (no dim_prior) : 5.8599
Best log-likelihood (dim_prior) : -1.8696
Log-likelihood array properties verified.
print_section("2b. Outlier Models")
# Compute outlier log-likelihoods for the observed object
lnl_chisq_outlier = chisquare_outlier_loglike(true_flux, obs_err)
lnl_uniform_outlier = uniform_outlier_loglike(true_flux, obs_err)
print(f"Chi-square outlier log-likelihood : {lnl_chisq_outlier[0]:.4f}")
print(f"Uniform outlier log-likelihood : {lnl_uniform_outlier[0]:.4f}")
print(f"Best normal model log-likelihood : {lnl.max():.4f}")
print("\nInterpretation:")
print(" If the best model lnl exceeds the outlier lnl, the object is well-fit.")
print(" If outlier lnl is higher, the object may be a contaminant or artifact.")
assert_array_properties(lnl_chisq_outlier, name="chisq_outlier", ndim=1, shape=(1,), finite=True)
assert_array_properties(lnl_uniform_outlier, name="uniform_outlier", ndim=1, shape=(1,), finite=True)
print("\nOutlier log-likelihood properties verified.")
2b. Outlier Models
==================
Chi-square outlier log-likelihood : -12.3016
Uniform outlier log-likelihood : 1.4963
Best normal model log-likelihood : 5.8599
Interpretation:
If the best model lnl exceeds the outlier lnl, the object is well-fit.
If outlier lnl is higher, the object may be a contaminant or artifact.
Outlier log-likelihood properties verified.
2c. Likelihood Comparison Plot
==============================
Saved: /home/user/brutus/tutorials/plots/tutorial_09/likelihood_comparison.png
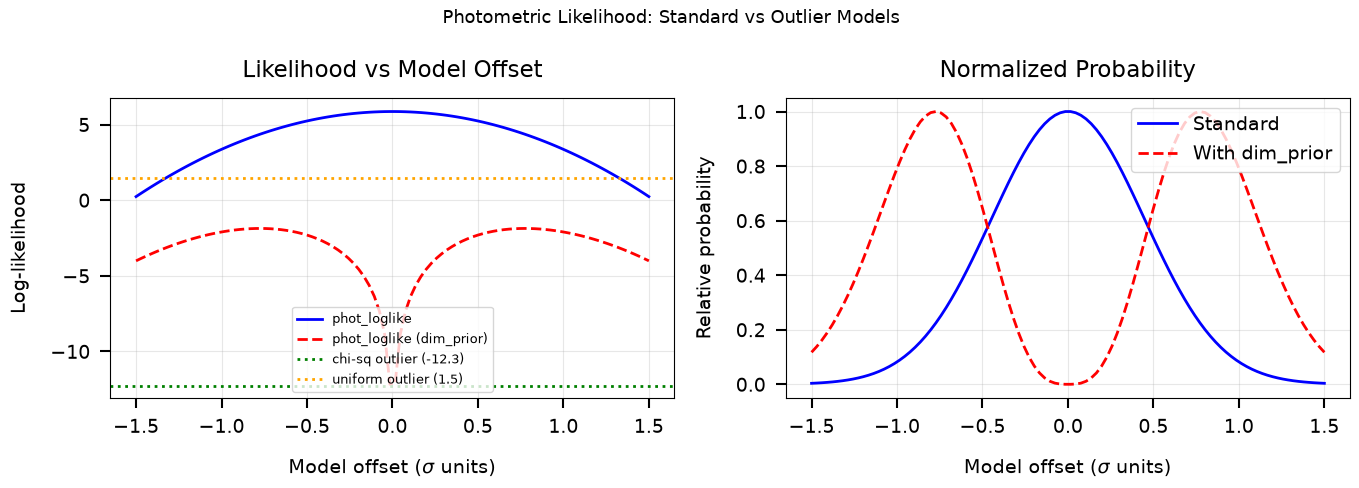
The standard likelihood peaks when model = data (offset = 0).
The dim_prior version additionally penalizes overfitting (too-perfect matches).
3. Mathematical Utilities#
The brutus.utils math module provides:
Fast 3x3 matrix inversion optimized for covariance matrices (
inverse3)Positive semi-definiteness check (
isPSD)Chi-square log-PDF (
chisquare_logpdf)Truncated normal PDF / log-PDF (
truncnorm_pdf,truncnorm_logpdf)
from brutus.utils import inverse3, isPSD
print_section("3a. Fast 3x3 Matrix Inversion")
# Create a random positive-definite 3x3 matrix
np.random.seed(99)
L = np.array([[2.0, 0.0, 0.0],
[0.5, 1.5, 0.0],
[0.3, 0.2, 1.0]])
A = L @ L.T # guaranteed positive-definite
print("Matrix A:")
print(A)
# Invert with brutus
A_inv = inverse3(A)
print("\nInverse A_inv:")
print(A_inv)
# Verify: A @ A_inv should be identity
product = A @ A_inv
print("\nA @ A_inv:")
print(product)
identity_error = np.max(np.abs(product - np.eye(3)))
print(f"\nMax deviation from identity: {identity_error:.2e}")
assert np.allclose(product, np.eye(3), atol=1e-10), "Inversion check failed"
print("Verification passed: A @ A_inv = I.")
3a. Fast 3x3 Matrix Inversion
=============================
Matrix A:
[[4. 1. 0.6 ]
[1. 2.5 0.45]
[0.6 0.45 1.13]]
Inverse A_inv:
[[ 0.29138889 -0.09555556 -0.11666667]
[-0.09555556 0.46222222 -0.13333333]
[-0.11666667 -0.13333333 1. ]]
A @ A_inv:
[[ 1.00000000e+00 -1.36927506e-17 -8.88178420e-17]
[ 4.25585493e-18 1.00000000e+00 -6.66133815e-17]
[-2.42028619e-17 -1.43773882e-17 1.00000000e+00]]
Max deviation from identity: 8.88e-17
Verification passed: A @ A_inv = I.
print_section("3b. Positive Semi-Definiteness Check")
# Test 1: positive-definite matrix (from above)
print(f"A (positive-definite covariance): isPSD = {isPSD(A)}")
# Test 2: identity matrix
I3 = np.eye(3)
print(f"Identity matrix: isPSD = {isPSD(I3)}")
# Test 3: zero matrix (positive semi-definite but not positive-definite)
Z3 = np.zeros((3, 3))
print(f"Zero matrix: isPSD = {isPSD(Z3)}")
# Test 4: matrix with a negative eigenvalue (NOT PSD)
bad_matrix = np.array([[1.0, 0.0, 0.0],
[0.0, -1.0, 0.0],
[0.0, 0.0, 1.0]])
print(f"Matrix with neg eigenvalue: isPSD = {isPSD(bad_matrix)}")
# Test 5: non-symmetric matrix (NOT PSD by definition)
nonsym = np.array([[1.0, 2.0, 0.0],
[0.0, 1.0, 0.0],
[0.0, 0.0, 1.0]])
print(f"Non-symmetric matrix: isPSD = {isPSD(nonsym)}")
assert isPSD(A), "PD matrix should be PSD"
assert not isPSD(bad_matrix), "Matrix with neg eigenvalue should not be PSD"
assert not isPSD(nonsym), "Non-symmetric matrix should not be PSD"
print("\nAll checks passed.")
3b. Positive Semi-Definiteness Check
====================================
A (positive-definite covariance): isPSD = True
Identity matrix: isPSD = True
Zero matrix: isPSD = True
Matrix with neg eigenvalue: isPSD = False
Non-symmetric matrix: isPSD = False
All checks passed.
3c. Chi-Square Log-PDF
======================
Saved: /home/user/brutus/tutorials/plots/tutorial_09/chisquare_comparison.png
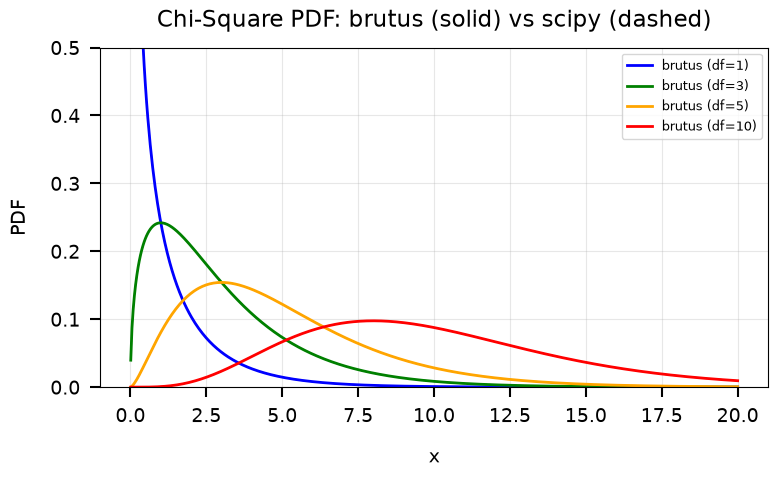
Max |log-PDF difference| for df=5: 1.78e-15
brutus and scipy chi-square log-PDFs agree to machine precision.
3d. Truncated Normal Distribution
=================================
Saved: /home/user/brutus/tutorials/plots/tutorial_09/truncnorm_comparison.png
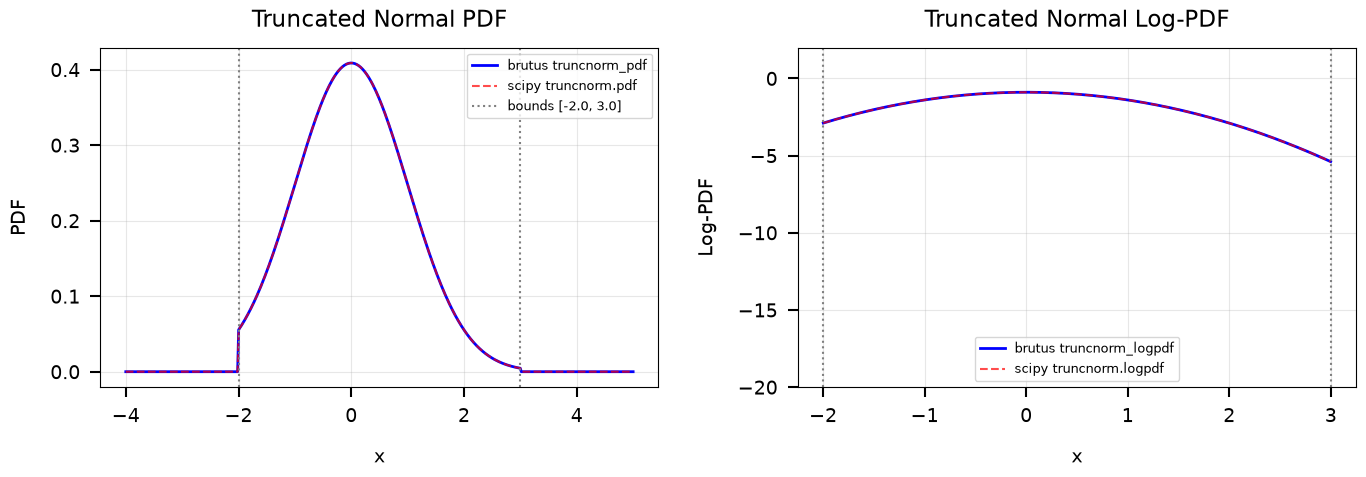
Max |PDF difference| in interior: 0.00e+00
Max |log-PDF difference| in interior: 0.00e+00
brutus and scipy truncated normal implementations agree.
4. Sampling Utilities#
These functions are used for posterior analysis after fitting:
Function |
Description |
|---|---|
|
Compute (weighted) quantiles from samples |
|
Draw from multiple multivariate normals simultaneously |
|
Draw from joint (scale, A_V, R_V) posterior |
from brutus.utils import quantile
print_section("4a. Weighted Quantiles")
np.random.seed(77)
# Unweighted case
samples = np.sort(np.random.normal(5.0, 1.5, size=10000))
q_values = np.array([0.16, 0.50, 0.84])
q_unw = quantile(samples, q_values)
print("Unweighted samples (N=10000, mean=5, std=1.5):")
print(f" 16th percentile : {q_unw[0]:.3f} (expected ~{5.0 - 1.5:.1f})")
print(f" 50th percentile : {q_unw[1]:.3f} (expected ~5.0)")
print(f" 84th percentile : {q_unw[2]:.3f} (expected ~{5.0 + 1.5:.1f})")
# Weighted case: heavily weight the upper tail
weights = np.where(samples > 6.0, 10.0, 1.0)
q_wt = quantile(samples, q_values, weights=weights)
print("\nWeighted samples (10x weight for samples > 6):")
print(f" 16th percentile : {q_wt[0]:.3f}")
print(f" 50th percentile : {q_wt[1]:.3f}")
print(f" 84th percentile : {q_wt[2]:.3f}")
print(f"\nWeighted median shifted from {q_unw[1]:.3f} to {q_wt[1]:.3f} (toward high values).")
assert_array_properties(q_unw, name="quantiles_unw", ndim=1, shape=(3,), finite=True)
assert_array_properties(q_wt, name="quantiles_wt", ndim=1, shape=(3,), finite=True)
assert q_wt[1] > q_unw[1], "Weighted median should be larger"
print("Quantile computations verified.")
4a. Weighted Quantiles
======================
Unweighted samples (N=10000, mean=5, std=1.5):
16th percentile : 3.492 (expected ~3.5)
50th percentile : 4.982 (expected ~5.0)
84th percentile : 6.506 (expected ~6.5)
Weighted samples (10x weight for samples > 6):
16th percentile : 5.077
50th percentile : 6.482
84th percentile : 7.480
Weighted median shifted from 4.982 to 6.482 (toward high values).
Quantile computations verified.
4b. Multivariate Normal Sampling
================================
Mean: [ 3. -1.]
Covariance:
[[1. 0.6]
[0.6 0.5]]
isPSD(cov) = True
Samples shape: (2, 2000) (dim, size)
Sample mean: [ 2.98417272 -1.00011614] (expected: [ 3. -1.])
Sample cov:
[[0.9792843 0.57710111]
[0.57710111 0.48133874]]
(expected:
[[1. 0.6]
[0.6 0.5]])
Saved: /home/user/brutus/tutorials/plots/tutorial_09/mvn_samples.png
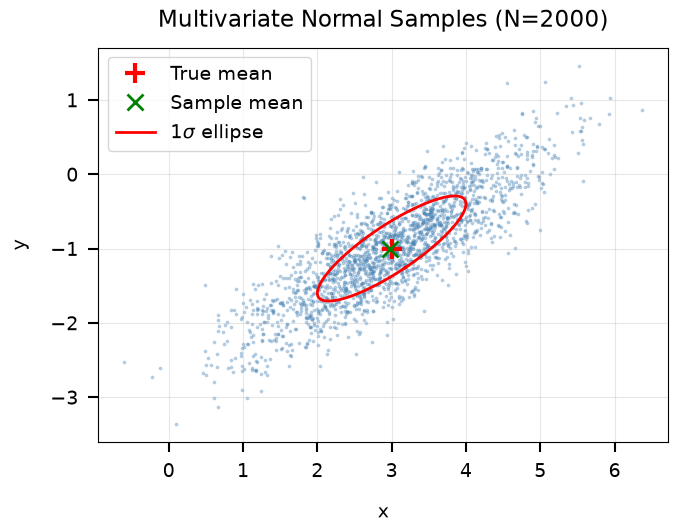
Sample distribution matches the specified mean and covariance.
4c. Scale Factor, Distance, and Extinction#
The draw_sar function draws correlated samples of (scale, A_V, R_V)
from the joint posterior at each model grid point. Understanding the
scale factor is key to interpreting these draws:
Scale represents the squared ratio of reference distance to true distance:
scale = (d_ref / d)^2 = 1 / d_kpc^2(sinced_ref = 1 kpcin brutus).To convert a scale draw to a distance:
d_kpc = 1 / sqrt(scale).Larger scale values correspond to closer objects; smaller scale values correspond to more distant objects.
Note that brutus now samples in log-distance space rather than
scale-space in the main fitting pipeline. Log-distance sampling provides
better importance sampling behavior, especially for distant or faint
sources where the posterior in scale-space becomes highly skewed.
The draw_sar utility remains available for cases where you need
correlated (scale, A_V, R_V) draws from the per-model covariance
matrices stored in BruteForce output.
What to look for in the plots below: The correlated (scale, A_V, R_V) draws illustrate how distance and extinction trade off – objects that are inferred to be closer (higher scale) tend to require less foreground extinction (lower A_V), and vice versa. The R_V draws show the additional uncertainty in the shape of the extinction curve.
4c. Drawing from (Scale, A_V, R_V) Posterior
============================================
Input parameters:
Model 0: scale=1.00, A_V=0.50, R_V=3.32
Model 1: scale=0.80, A_V=1.00, R_V=3.30
Model 2: scale=1.20, A_V=2.00, R_V=2.80
Draw shapes: scale=(3, 500), A_V=(3, 500), R_V=(3, 500)
All draws within specified bounds (A_V: [0, 6], R_V: [1, 8]).
Saved: /home/user/brutus/tutorials/plots/tutorial_09/draw_sar.png
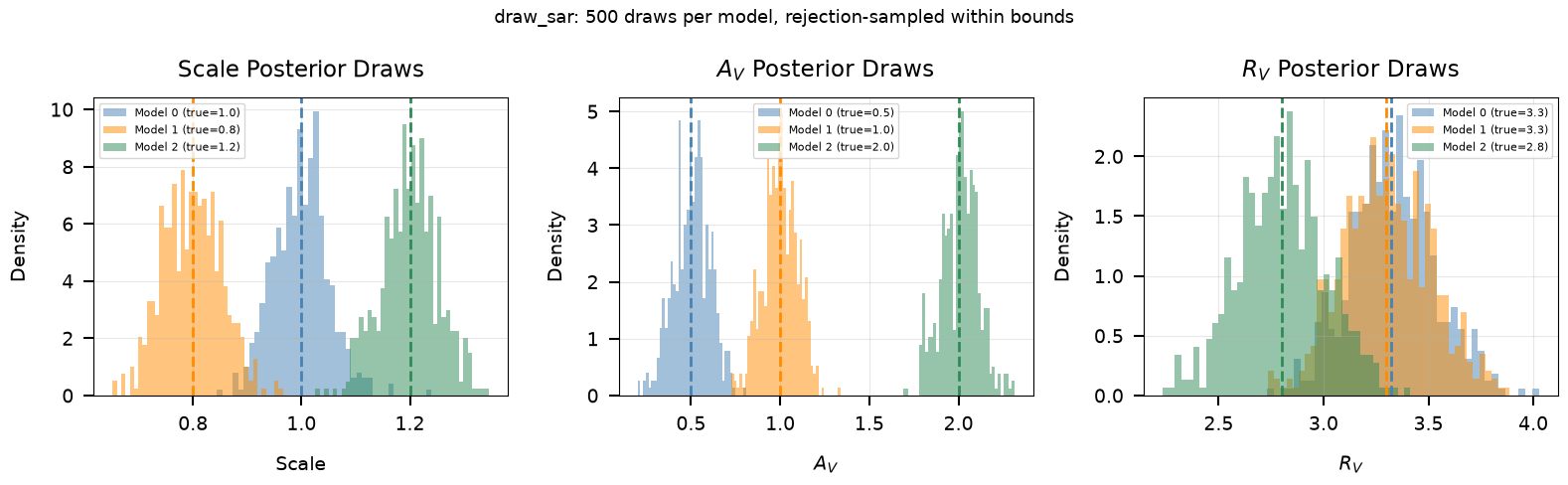
Draws are centered on input values and respect physical bounds.
Summary#
This tutorial demonstrated the utility functions available in brutus.utils:
Photometry Conversions (Section 1)#
magnitude/inv_magnitudeprovide exact round-trip conversion between flux and AB magnitudes.luptitude/inv_luptitudeprovide asinh magnitudes that remain well-behaved at faint fluxes where standard magnitudes diverge.add_magcombines fluxes expressed as magnitudes.
Photometric Likelihoods (Section 2)#
phot_loglikeis the core likelihood function used in BruteForce fitting. The optionaldim_priorflag adds a chi-square dimensionality penalty.chisquare_outlier_loglikeanduniform_outlier_loglikeprovide baseline log-likelihoods for identifying outlier objects that no stellar model can fit.
Mathematical Utilities (Section 3)#
inverse3provides fast, numba-accelerated 3x3 matrix inversion optimized for covariance matrices.isPSDchecks whether a matrix is positive semi-definite, which is required for valid covariance matrices.chisquare_logpdfandtruncnorm_pdf/truncnorm_logpdfreplicate scipy distributions with lightweight implementations.
Sampling Utilities (Section 4)#
quantilecomputes weighted quantiles from posterior samples, essential for credible intervals.sample_multivariate_normaldraws from many multivariate normal distributions simultaneously using Cholesky decomposition.draw_sargenerates rejection-sampled posterior draws for (scale, A_V, R_V) within physical bounds.
Next Steps#
These utilities are used throughout the brutus fitting pipeline. See:
Tutorial 5 for how
phot_loglikedrives the BruteForce fitterTutorial 6 for how
draw_sarandquantileappear in cluster analysisTutorial 8 for how photometric offsets interact with magnitude conversions